

데이터 기반 피드백이란 야구에 관한 질문을 바꾸는 과정 (신동윤)
1. 옳은 것 vs 실행가능한 것
데이터 기반 피드백이란 단순하게 생각하면 ‘객관적 데이터를 바탕으로 옳은 방향을 제시하는 것’이다. 하지만 이런 이해는 절반은 맞지만 절반은 틀렸다. 그에 앞서 질문하는 방법을 바꾸는 것이 필요하다. 그게 안되면 맞았다고 말한 절반조차 쓸모없는 것이 된다.
해설가 시절의 차명석 단장이 남긴 어록 중에 이런 것이 있었다. (타자가 좋으니까 어려운 승부를 하라는 주문에 대해)
“스트라이크 존에서 볼 1~2개 빠지는 볼을 던지라고 합니다. 걸려들면 다행이고 안 걸려들면 포볼로 거르라는 것이죠. 근데 그게 정말 말도 안 되는 주문인게요, 그렇게 정교하게 컨트롤할 수 있으면 잡아내야지 왜 거릅니까?”
어렵게 승부하라는 주문은 아마 객관적 사실에 근거하고 있을 것이다. 투수의 능력과 상대할 타자에 대한 객관적 분석에 근거했을 것이다. 하지만 그렇다고 해서 이 ‘옳은 주문’이 실행가능한 것이 되지는 않는다. 실행가능하지 않은 주문은 쓸모가 없다.
KBO리그를 기준으로 했을 때 속구 구속이 5km/h 빨라질 수록 헛스윙비율은 3-5%p 정도 높아진다. 헛스윙비율은 탈삼진능력과 강하게 연관된 지표다. 따라서 승부처의 투수가 155km/h짜리 속구를 던진다면 더할 나위없이 강력한 무기가 된다. 이것은 분명히 객관적 사실에 근거하고 있다. 하지만 ‘더 빠른 공을 던져’ 이런 주문이 도움이 될리가 없다.
야구는 점점 더 많은 데이터를 활용하는 쪽으로 변화하고 있다. 데이터의 가치는 사실에 근거한 ‘옳은 정보’를 제공해 준다는 것이지만 옳다는 것과 실행가능하다는 것은 다르다. 데이터 기반 피드백의 바탕에는 우선 활용가능한 데이터, 또는 수집하려고 하는 데이터들을 ‘알아도 못하는 것’부터 ‘알면 할 수 있는 것’까지 여러 차원으로 구분하는 작업이 있어야 한다.
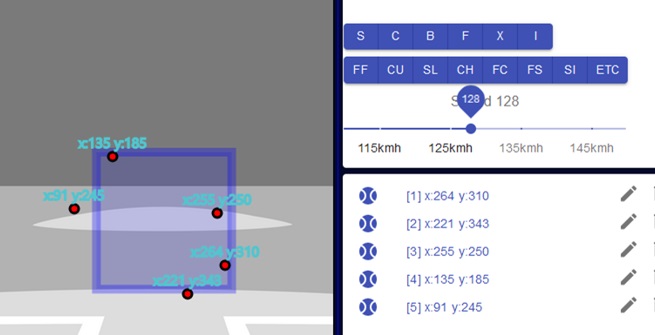
‘알아도 못하는 것’과 ‘알면 할 수 있는 것’을 왼쪽부터 오른쪽으로 늘어 놓는다면, 구속은 가장 왼쪽에 있을 것이다. 의도한 곳, 아마도 공략하려는 타자의 약점코스에 공을 던지는 것도 구속 만큼은 아니지만 역시 상당히 왼쪽에 있다.
반면 투수의 구종선택은 휠씬 더 오른쪽에 있다. 굉장한 공을 아슬아슬한 곳에 제구하는 것은 알아도 못하는 것이지만, 특정한 타자를 상대로, 특정한 볼카운트에서 어떤 구종을 선택할 것인가는 옳은 정보가 있다면 실행할 수 있다. 투수 자신이 가진 구종 중에서, 왼손타자 혹은 오른손타자를 상대할 때 더 잘먹히는 구종을 안다면 어렵지 않게 피칭에 써먹을 수 있다.
데이터 기반 피드백은 우선 ‘알면 할 수 있는 것’에 집중하는 것이다. 그러려면 데이터를 유용하게 써먹을 수 있는 영역이 어디인지 분간해 내는 것이 먼저 필요하다.
2. 어떻게 치는가 vs 어떤 공을 치는가
좋은 타자는 잘친다. 그런데 잘친다는 것은 매우 종합적인 결과다. 다른 선수가 따라할 수 없는 선천적 능력과 관련된 부분도 있다. 이런 것은 ‘어떻게 하면 잘 칠 수 있을까?’라는 질문에 답할 수 있는 ‘옳은 데이터’가 있다고 해도 실행가능하지 않다. 더구나 운동 메카니즘의 많은 부분은 현대의 가장 뛰어난 기술이나 장비로도 필요한 만큼의 정보를 수집할 수 없다.
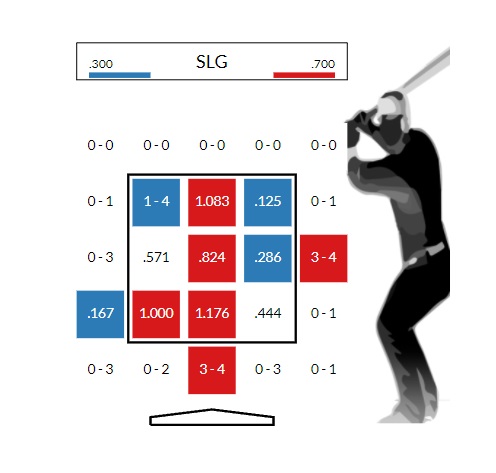
하지만 데이터 기반 피드백의 영역은 여전히 남아 있다. 타격과 관련된 데이터분석이 알아낸 것은, 좋은 타격결과란 ‘어떻게 치는가’ 뿐 아니라 ‘어떤 공을 쳤는가’에도 좌우된다는 점이다. 슬럼프를 겪고 있는 타자들은 대체로 ‘어떤 공을 때리는가’에서 변화를 보인다. 이런 것은 새로운 기술이나 비싼 장비 없이도 수집할 수 있는 데이터다.
새로운 질문은 좋은 타자의 정의도 바꾼다. 좋은 타자란 (아무 공이나) 잘치는 타자가 아니라, 좋은 결과가 나올만한 공을 치는 타자다. 물론 좋은 공을 고를 수 있는 것 역시 특별한 능력이라 안다고 실행할 수 있는 것은 아니다. 대신 질문이 달라지면 대답도 달라진다.
‘어떻게 하면 잘 칠 수 있을까?’ 라는 질문에 데이터는 쓸만한 답을 하기 어렵다. 하지만 질문을 바꾸어서 ‘어떤 공을 쳤을때 좋은 결과가 나오고 있는가?’라고 물을 때는 적어도 무엇을 해야 할지, 어디를 바라봐야 할지 힌트를 준다.
첫째, ‘어떻게 치는가’ 만큼 ‘어떤 공을 치는가’는 좋은 결과를 내는데 중요하게 작용한다.
둘째 프로레벨의 타자라도 자신이 어떤 공을 쳤을때 좋은 결과가 나오는지 잘 모른다.
셋째, ‘어떻게 치는가’와 달리 ‘어떤 공을 쳤는가’는 객관화할 수 있는 정보다.
이 세가지는 데이터 기반 피드백의 본질이다. 정보가 있으면 실행가능한 영역이라는 점, 이전에는 몰랐던 새로운 정보라는 점, 그리고 관찰자나 전달자의 주관과 선입견이 배제된 객관적 정보를 선수가 직접 접할 수 있다는 점이다.
3. 내가 어떤 공을 던지는가 vs 내 공이 타자에게 어떻게 보이는가
현재 KBO리그 구단 대부분은 투구추적시스템을 통해 얻는 데이터를 사용한다. 어떤 선수들은 이 데이터를 활용해서 새로운 구종을 개발하거나 기존의 구종을 조정하고 개선한다. 타자를 상대하는 전략을 바꾸기도 한다. 뚜렷한 성과를 내는 사례도 있다.
하지만 데이터활용을 잘 하고 성과를 낸다고 하는 선수들 조차, 데이터를 아주 분석적으로 사용하지는 않는다. 전력분석팀의 도움을 받아 의미있는 힌트와 방향을 찾아내고 결국은 자신의 방법으로 소화해야 한다. 그런데 그 과정에서 재미있는 변화가 관찰된다. 자신의 피칭을 표현하는 언어가 바뀐다.
그것이 바로 ‘내 공이 타자에게 어떻게 보일까?’라는 질문이다. 힌트를 얻는 것은 고가의 장비로 측정한 투구추적데이터이고, 또 그것을 해석해주는 전문적 분석가의 도움을 통해서지만, 실제로 그것을 자신의 피칭에 적용할 때는 동료 타자들의 의견을 듣는다. 하지만 이전과 달라진 것은, 질문이 바뀌었다는 것이다. 내 공이 얼마나 빠르고 내 공이 얼마나 날카롭게 변화하는가가 아니라, 그래서 내 공이 타자들에게 어떻게 보이느냐에 관심을 갖기 시작한다.
이것이 데이터 기반 피드백이 작용하는 방식이다. 선수의 플레이와 퍼포먼스를 객관화해서 이전에는 몰랐던 선수 자신의 플레이를 이해하도록 돕는다. 야구에서 투수는 아주 역설적인 존재다. 세상 모든 사람이 그 투수의 공을 타자 시점에서 볼 수 있지만, 오직 투수 본인은 자신의 공을 타자의 시점으로 볼 방법이 없다. 따라서 투수는 자신이 던진 공에 대해, 그 공이 초래할 결과에 대해 많은 피드백을 받는다고 해도 그것을 어떻게 이해하고 소화할지 자신만의 체계를 만들어야 한다. 그렇지 못할 경우 피드백의 효과는 결정적으로 반감된다.
데이터 기반 피드백이란 선수가 자신의 플레이를 객관적으로 인식하는 것을 돕기 위한 프로그램이다. 그리고 그걸 바탕으로 꼭 숫자 데이터가 아닌 정보라도 선수가 다양한 커뮤니케이션에 주도적으로 뛰어들 수 있도록 유도한다.
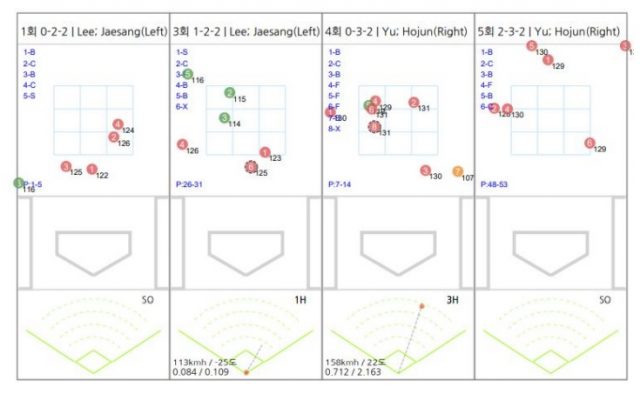
데이터 기반 피드백이, 다른 접근에 비해 휠씬 더 ‘옳은 정보’를 제공하는 것은 아니다. 게다가 측정하고 수집할 수 있는 데이터가 제한되어 있는 경우라면, 다루지 못하는 사각지대를 많이 남겨놓게 된다. 하지만 이런 것은 결정적인 문제가 되지 않는다.
데이터 기반 피드백이 의도하는 것은,
1. 관찰자나 전달자의 주관, 철학이 개입되지 않은,
2. 실제로 선수의 플레이와 관련되어서 어떤 일이 일어났는지 객관적으로 표현한 데이터를
3. 선수가 직접 보고 생각할 수 있는 것을 통해
4. 선수가 자기인식체계를 가질 수 있도록
돕는 것이다.
글 : 신동윤 (데이터인플레이 대표, 한국야구학회 이사)
우리야구 8호에 소개된 글입니다. 격월간 우리야구 구입은 우리야구 스토어!








